Category Archives: General

Good news from and for MariaDB Foundation: in Schaffhausen Institute of Technology (SIT), we have a new Platinum Sponsor. With the additional funds and with the insights provided by Serguei Beloussov, who will work with the MariaDB Foundation on the board level, we expect to improve our ability to further the MariaDB Foundation mission related to our values of Openness, Adoption, and Continuity.
Introducing SIT
This event marks a first in our work with sponsors, given that our top-level sponsor list has so far contained only names fairly familiar to industry players: DBS Bank, Visma, IBM, Microsoft, Alibaba, Tencent, and Service Now, not to mention the eponymous MariaDB Corporation.
…
Continue reading “New Sponsor: Schaffhausen Institute of Technology”

At the MariaDB Foundation, we want MariaDB Server to be a model citizen in the Open Source world. For now, there is a sizeable gap between dreams and reality. But that doesn’t stop us from striving to improve. Let me here describe some of our challenges, and share some visions of where we want to be.
Continuous Integration
One pain point is the state of the development tree. A model citizen would ensure that the tree can always be built. Every day, all the features under development could be tested by the community, on all platforms.
…
Continue reading “Challenges and Visions for MariaDB Server”
At MariaDB Foundation, we have many reasons to be thankful towards all of those who have helped us during 2020.
A few sample contributions
We have recently expressed our gratitude towards contributors in our ecosystem, in 2020. Daniel Black explicitly thanked Tencent for their contributions, and Vicentiu Ciorbaru for the ARM related contributions.
On the same note, Intel has given us access to hardware and software to enable builds using Intel compilers, but more on that once we can release these new builds.
…
It’s been close to four months since we announced our new project of renewing MariaDB Downloads. We are now ready to launch our first version. We have done a lot of work behind the scenes which will simplify further developments. A technical breakdown post is coming, but for now, let’s focus on the new features!
In with the new
User friendliness – one click to download
User friendliness is at the core of MariaDB (going all the way back to MySQL times). It should be really easy to download, install and run MariaDB.
…

How do you select a database in practice? How do you pretend to select it? And, if you want to be serious, how do you select it logically?
Those are the key questions I dug into, during my keynote last week at Percona Live Online.
For those who feel they don’t want to listen to the entire 30 minute video of the presentation, I have compiled a number of entry points for you below:
- 0:23 Silly hat meme, “Teknologmössa”
- 2:19 Agenda
- 2:43 Choosing a database in practice
- 3:59 Pretending to choose a database
- 5:00 Triggers for making a fresh choice
- 5:51 Monetary impulses
- 7:53 Database lifecycle impulses
- 10:07 MariaDB 5.5 on Github
- 11:24 Framework for database choice: 1.
…
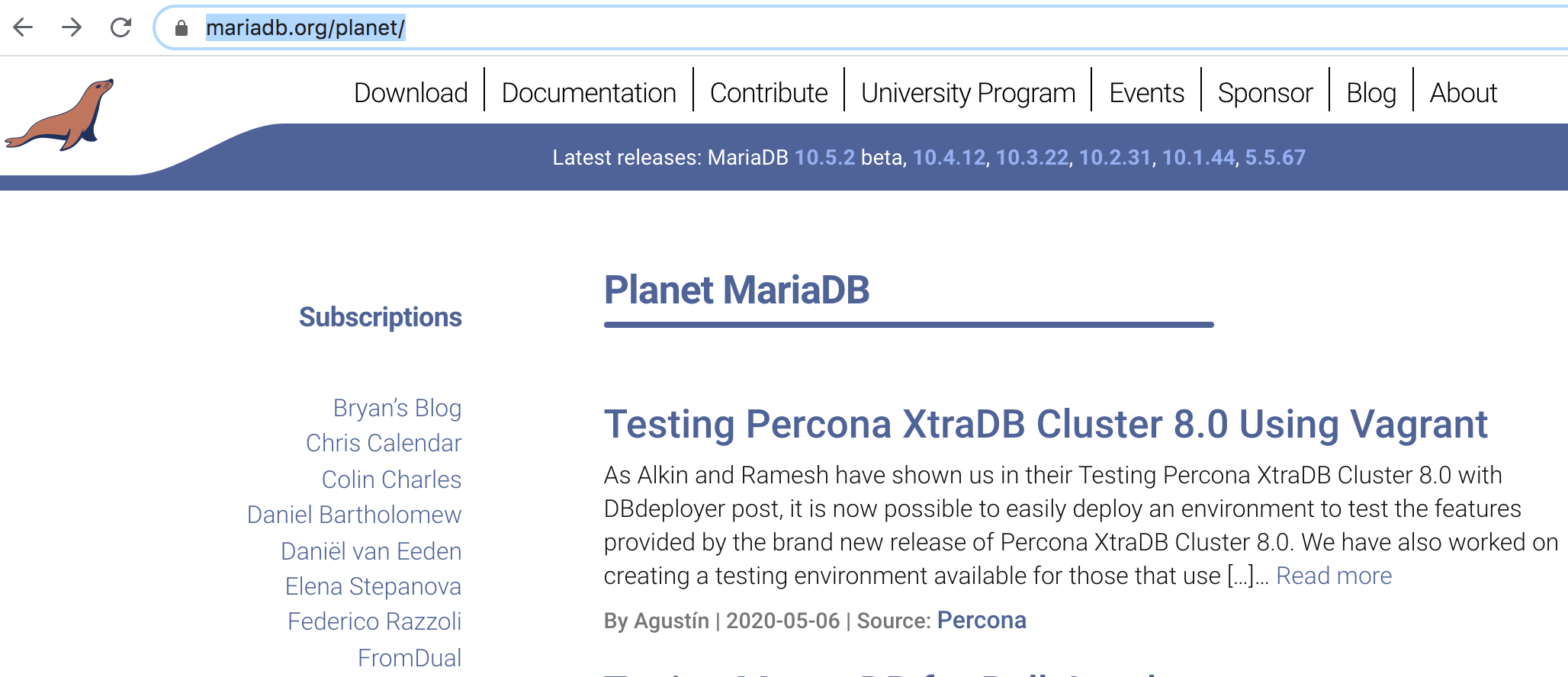
Planet MariaDB has been reworked from scratch, getting a new instance with the same look and feel as the rest of mariadb.org.
Three news items, related to that: One bad, one neutral, one good. I’m saving the good one for last, as I hope you will like it.
Bad news: The old Planet had five different RSS feeds, we now have only one. We maintain the format changes only on one RSS feed, which means that some of you will have to update your RSS feed to https://mariadb.org/planet-feed.xml (also listed on Planet MariaDB). That said, we are working on further redirects;
…
Continue reading “Planet MariaDB underwent liberal facelift”

Congratulations, MariaDB Corporation, on releasing SkySQL, a DBaaS offering for MariaDB Server! This is a big step for MariaDB Corporation, and we in the MariaDB Foundation hope it’s going to be a success for you and for MariaDB Server.
We welcome SkySQL as a further contributor to the adoption of MariaDB Server, and look forward to it driving in new categories of users.
To find out more, check out https://mariadb.com/skysql/.
…
Continue reading “Congratulations on SkySQL, the DBaaS offering!”

Time to renew downloads.mariadb.org! We are embarking on a long project. A large part of our user base mainly interacts with us through downloading new versions. Renewing MariaDB Downloads is the biggest-impact project of all of 2020, for that part of our user base.
Projects like this often get launched when external and internal impulses coincide. Our users have asked for a more consistent, simpler user experience. Advanced users would like a programmatic interface (a.k.a. REST API) for part of the functionality. And the current codebase needs refactoring attention, as it has served past its best-before date.
…