Tag Archives: development

One of the corner stones in MariaDB Foundation’s mission is:
We strive to increase adoption by users and across use cases, platforms and means of deployment.
MariaDB Server plugins are definitely a prime “means of deployment” for server features. But a relatively neglected one so far. They have been around for many years. But, somehow, they have escaped the user’s focus. Why that happened is a very interesting topic. And one that I’d definitely like to hear your opinion on!
Which brings me to my main topic: How do we all change that?
…

This is the last post in the “MariaDB Vector: How it works” series. The first three were about storage, in-memory representation, HNSW modifications. Everything that was done in MariaDB 11.8. This post talks about new feature in MariaDB 12.3: optimized distance calculation.
As I mentioned earlier, distance calculation is the most time consuming part of the vector search, taking 80–90% of the total search time. Also it is linear on the number of dimension — computing the distance between vectors of 1536 dimensions takes twice as long compared to vectors of 768 dimensions.
…

In the previous parts of this series we’ve seen how MariaDB stores vector indexes in a table and how to implement HNSW for a good performance. But MariaDB is not implementing HNSW, it calls its vector search algorithm mHNWS, a modified HNSW. Let’s see how exactly it was modified.
Not so greedy!
HWNS, like many, if not most, graph based vector search algorithms is greedy. Think of it this way, when it needs to find just one nearest vector (ef=1), it will walk the graph always choosing the node that will take it the closest to the target at this particular step.
…

In the first post of this series, I’ve described how the vector index is stored in a table and how it achieves full transactional behavior and ACID properties compatible with the storage engine of the table the user created. But while the table provides persistent storage of the index, it’s in-memory part that gives it the performance. This is how it works.
Distance calculations
This is the most performance sensitive part of the HNSW. According to various estimates, distance calculations account for 80–90% of search time. And this operation time grows linearly with the vector length.
…

You might have seen that MariaDB Vector is fast. And is getting faster. But why? How does it achieve that? And why it is said to use mHNSW (modified HNSW) algorithm? What did it modify in the conventional HNSW that all other databases are using? Let’s take it apart and analyze piece by piece.
Introduction into HNSW
This post is not a full description of HNSW, there are many HNSW descriptions online and they are good, better than what I could’ve written. I will only show the basic concepts beyond HNSW, concepts that are crucial for the rest of the post.
…
Earlier I posted that this presentation was about to happen, and it did! I presented to a keen audience of over 20 people live, and number who watched later (it was in a rather early US time, however attracted a number of attendees from Europe, India, Thailand all the way to east of Australia at UTC+10:30.
Below is the video, and the slide outline is available.
The journey to this presentation began as a request to update our Clang version that we use in Buildbot, MariaDB’s CI system.
…
Continue reading “Deep dive into Clang sanitizer testing with MariaDB (Post Event)”
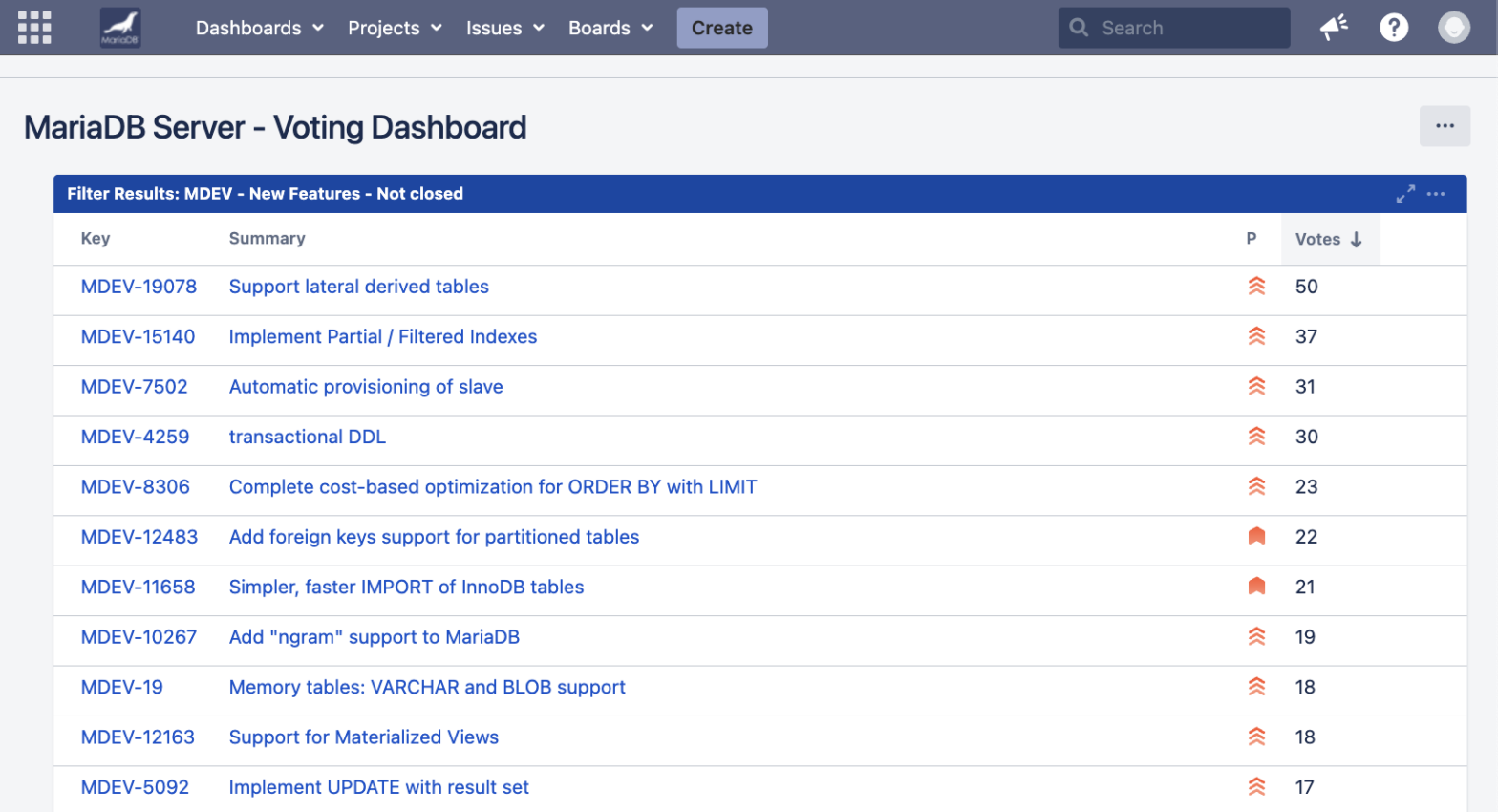
MariaDB has had a voting feature in its issue tracker Jira since the dawn of time, but it hasn’t got much active attention. Despite that, there are now many Jira community items that have collected a fair amount of votes over the years.
Many items are now in limbo—not on the MariaDB road map, but not rejected either. We would like to better understand how to act on these.
More votes, and preferably more detailed comments on syntax and desired functionality or insights on use cases, would help the MariaDB Foundation and Corporation a lot in deciding what to do and how to prioritize resources.
…

We recently had a public vote on whether “main” or a version branch should be the default. The results in favour of “main” were very clear. It has been just over a month, but behind the scenes we have been laying the groundwork for this to happen.
We think we are as ready as we can be, so with the opening of development for 11.7, we have switched to “main” as the default branch for MariaDB Server. This means that all new feature development should now target the “main” branch when contributing to MariaDB Server.
…