Tag Archives: MariaDB
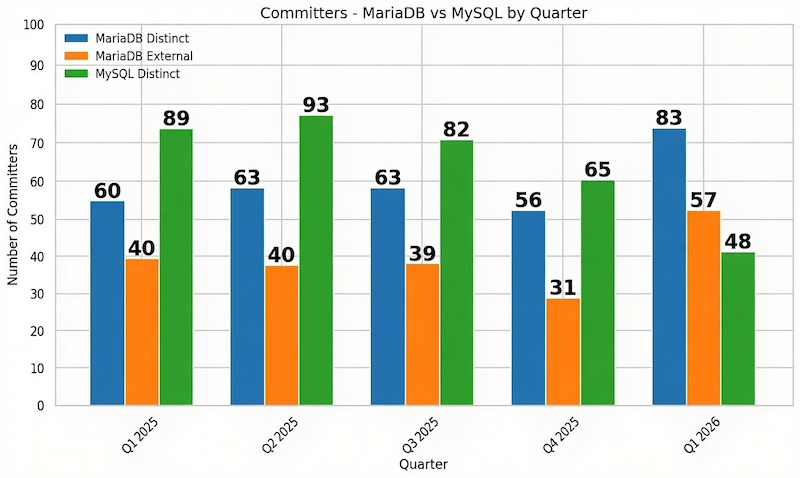
Inspired by some recent LinkedIn posts, I decided to take the AI in my own hands and do some stats on the MariaDB and MySQL repositories.
This graph is what I’ve got.
Not only have MariaDB Server distinct contributors surpassed the distinct MySQL Server contributors count! The External MariaDB contributors alone did! *
This is how the Power Of the Community looks like!
- You get to use a more functional, performant and error free MariaDB Server
- You get a say in shaping the future of the MariaDB Server.
…
…
Continue reading “MariaDB Foundation: Bringing TPC-B Back To Life”
If you ever considered contributing code to the MariaDB server, you should know that this is an intricate process involving multiple steps and multiple actors. To help you see your contributions successfully merged into the MariaDB Server codebase I’ve compiled a comprehensive description of the contribution process itself, the roles involved into it, the sequence of actions and conditions for transition from one to another. There’s even a diagram!
Please go to COMMUNITY_CONTRIBUTIONS.md.
This of course is going to be a moving target! I fully intend to keep the document up to date and enhance it with clarifications and process changes as they happen.
…
Continue reading “Documented: The MariaDB Server (Community) Contribution Process”

In the previous parts of this series we’ve seen how MariaDB stores vector indexes in a table and how to implement HNSW for a good performance. But MariaDB is not implementing HNSW, it calls its vector search algorithm mHNWS, a modified HNSW. Let’s see how exactly it was modified.
Not so greedy!
HWNS, like many, if not most, graph based vector search algorithms is greedy. Think of it this way, when it needs to find just one nearest vector (ef=1), it will walk the graph always choosing the node that will take it the closest to the target at this particular step.
…

In the first post of this series, I’ve described how the vector index is stored in a table and how it achieves full transactional behavior and ACID properties compatible with the storage engine of the table the user created. But while the table provides persistent storage of the index, it’s in-memory part that gives it the performance. This is how it works.
Distance calculations
This is the most performance sensitive part of the HNSW. According to various estimates, distance calculations account for 80–90% of search time. And this operation time grows linearly with the vector length.
…
We are pleased to announce the availability of a preview of the MariaDB 13.0 series. MariaDB 13.0 is a preview rolling release, published on 23 March 2026, and it continues the work started in 12.3 while adding a solid set of entirely new features.
And this one is interesting.
This preview release brings a nice mix of new SQL capabilities, better optimizer insight, richer metadata, and practical engine improvements. Not every feature is flashy, but many of them are exactly the kind of changes that make daily work with MariaDB smoother, clearer, and just a bit more powerful.
…

You might have seen that MariaDB Vector is fast. And is getting faster. But why? How does it achieve that? And why it is said to use mHNSW (modified HNSW) algorithm? What did it modify in the conventional HNSW that all other databases are using? Let’s take it apart and analyze piece by piece.
Introduction into HNSW
This post is not a full description of HNSW, there are many HNSW descriptions online and they are good, better than what I could’ve written. I will only show the basic concepts beyond HNSW, concepts that are crucial for the rest of the post.
…
I have recently completed a large project to implement a new improved binlog format for MariaDB. The result will be available shortly in the upcoming MariaDB 12.3.1 release.
In this article, I will give a short overview of the new binlog implementation. For more details, check the documentation which is in the source tree as the file Docs/replication/binlog.md, or here: https://github.com/MariaDB/server/blob/knielsen_binlog_in_engine/Docs/replication/binlog.md
EDIT: Also see Mark Callaghan’s benchmark of the new feature.
Using the new binlog
To enable the new binlog, configure the MariaDB server with binlog_storage_engine=innodb.
Additionally, the binlog must itself be enabled as usual using the option log_bin.
…
Continue reading “New binlog implementation in MariaDB 12.3”