Tag Archives: mysql

The news has circulated quietly in industry corners, but the implications are far too significant to brush aside: Oracle seems to have ended the Open Source era of MySQL.
I am not a spokesperson for Oracle, yet the signs are unmistakable. Entire teams associated with MySQL at Oracle have been dissolved, spanning engineering, development and sales. On LinkedIn, I’ve received a wave of messages from former colleagues — both long-time MySQL veterans and those who joined Oracle years after MariaDB was founded in 2009.
The impression is clear: Oracle has made a rational business decision to pivot towards AI and cloud, where MySQL only matters insofar as it strengthens OCI and Heatwave.
…
Continue reading “When Oracle Drops the Ball: Why MariaDB is the Future of the MySQL World”

We’re here, we’re open source, and we have RDBMS based Vector Search for you! With the release of MariaDB 11.6 Vector Preview, the MariaDB Server ecosystem can finally check out how the long-awaited Vector Search functionality of MariaDB Server works. The effort is a result of collaborative work by employees of MariaDB plc, MariaDB Foundation and contributors, particularly from Amazon AWS.
Previously on “MariaDB Vector”
If you’re new to Vector, this is what’s happened so far:
- We blogged a number of times about our view of where Gen AI belongs in MariaDB Server
- We showed a first demo in February at our FOSDEM Fringe Event
- We launched a project page on mariadb.org/projects/mariadb-vector/, containing a number of videos
- We went on stage at Intel Vision in London, with AI everywhere
- We blogged about Amazon’s take on Vectors and MariaDB, in “MariaDB is soon a vector database, too“
The main point: MariaDB Vector is ready for experimentation
…
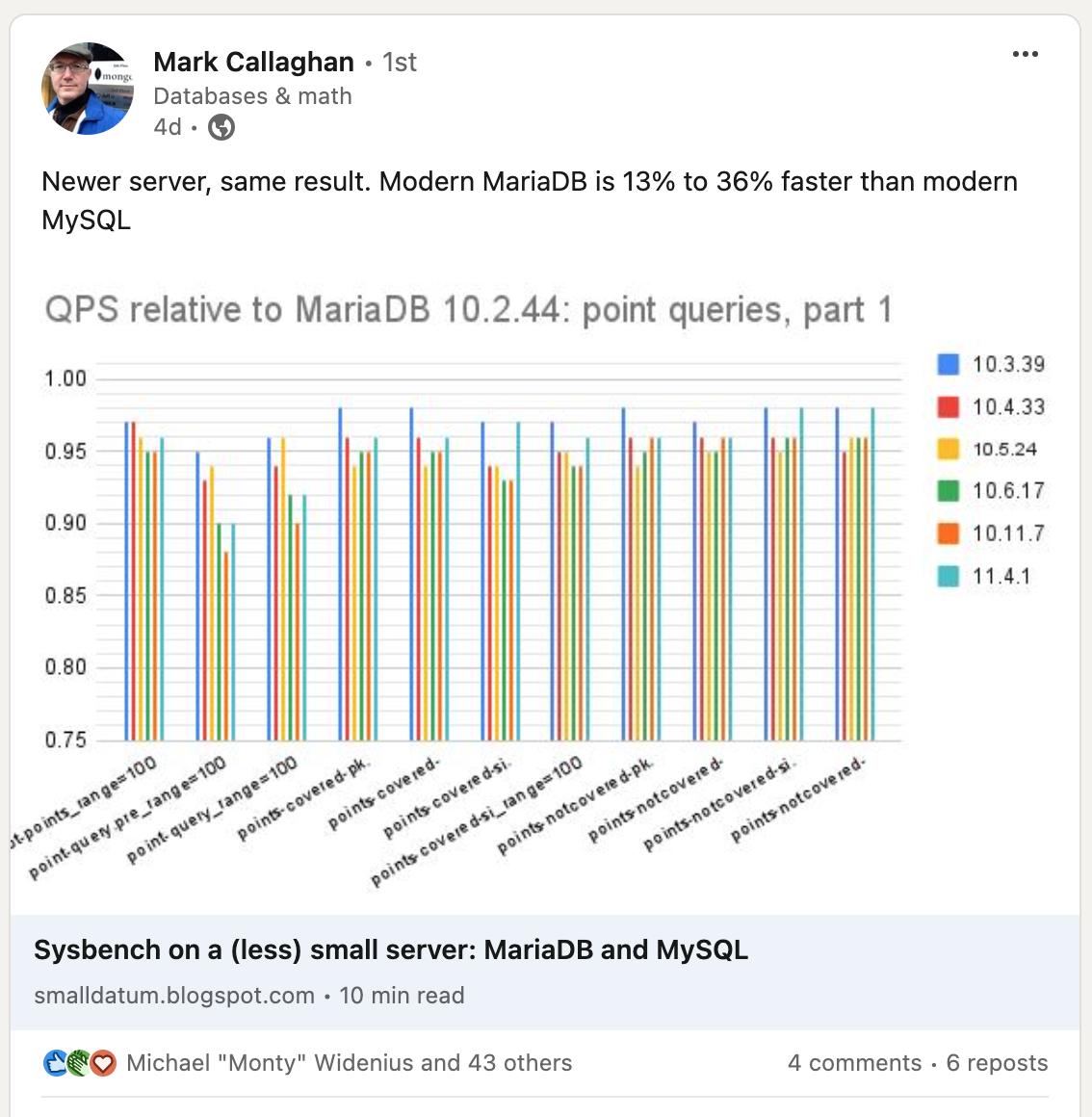
Is performance important for you, along with the latest features and long-term support? Go with MariaDB 11.4. But don’t take our word for it. We asked well known benchmarking expert Mark Callaghan to check out a number of MariaDB and MySQL releases, hit them hard with a tool of his choice, and share his findings.
MariaDB’s performance is stable over the years
The outcome: On the low concurrency load (high concurrency results are being prepared), MariaDB maintained stable performance over the last 10 years and 14 releases, while MySQL performance dropped almost by a third.
…
Continue reading “How MariaDB and MySQL performance changed over releases”

Dear users of MySQL 5.7 (or 8.0)!
Are you interested in getting help migrating to MariaDB 10.6 or 10.11, the latest long-term support releases? Are you coming to Brussels for FOSDEM in February? Do you have an open attitude, not minding to show a bit of dirty laundry in front of other users?
Then you may be a perfect candidate for our MariaDB Migration Workshop at our pre-FOSDEM event on Friday 2 Feb 2024. The workshop will be led by none other than the father of both MySQL Server and MariaDB Server, namely Michael “Monty” Widenius.
…

SSL (let’s call it that, even though SSL 2.0 and SSL 3.0 were long replaced by TLS 1.0–1.3 protocols) support was implemented in MySQL in 2001, so MariaDB (born in 2009) always had it. But over more than twenty years of SSL support there was one huge problem with it. It required tedious manual configuration, so most users never bothered and accepted the fact that their queries and data were sent unprotected. Which might have been slightly risky in 2001, but is definitely reckless in 2023.
The traditional approach
Let’s see. First, the user installing MariaDB or MySQL has to generate a private key and a certificate.
…
Continue reading “Mission Impossible: Zero-Configuration SSL”
We hear you, Kristian Köhntopp! Thank you for taking the time to articulate what many others are probably thinking.
For those of you to whom this sounds cryptic, let me share how I interpreted Kristian Köhntopp’s blog MySQL: Ecosystem fragmentation (https://blog.koehntopp.info/2020/10/28/
mysql-ecosystem-fragmentation.html), published last week:
Kristian noted that the question “Which version of MySQL do you run on?” for a long time hasn’t been merely answered by a simple version number, since there are reasons to perceive MariaDB and Aurora to be “variations to the same theme”.
…

How do you select a database in practice? How do you pretend to select it? And, if you want to be serious, how do you select it logically?
Those are the key questions I dug into, during my keynote last week at Percona Live Online.
For those who feel they don’t want to listen to the entire 30 minute video of the presentation, I have compiled a number of entry points for you below:
- 0:23 Silly hat meme, “Teknologmössa”
- 2:19 Agenda
- 2:43 Choosing a database in practice
- 3:59 Pretending to choose a database
- 5:00 Triggers for making a fresh choice
- 5:51 Monetary impulses
- 7:53 Database lifecycle impulses
- 10:07 MariaDB 5.5 on Github
- 11:24 Framework for database choice: 1.
…

At MariaDB Foundation, we are proud of MariaDB Server getting plenty of contributions. But we don’t want to get cocky, so here is an update about where we stand, and what we want to make happen.
First, we have shown our contribution pride in several places. On 15 February 2019, I tweeted
On code contributions, #MariaDB beats #MySQL 1009 to 247: We have over a thousand (1009) closed pull requests on github (and 179 open), MySQL has 247 closed (1 open). https://t.co/32NIuMMTvc pic.twitter.com/ZZcRBdk939
— Kaj Arnö (@kajarno) February 15, 2019
Repeating: On code contributions, #MariaDB beats #MySQL 1009 to 247: We have over a thousand (1009) closed pull requests on GitHub (and 179 open), MySQL has 247 closed (1 open).
In our Annual Report 2018, we spent several pages, talking about pull requests and patches, showing code contribution statistics. …